

Consistent hashing
Where load balancing finds its 'sweet spot' in distributing the load!


Have you ever faced traffic on the road? I guess you have, at least one time in life, just like how GPS routes you efficiently through city traffic,
Consistent Hashing (GPS) ensures your data finds its way home (your destination), no matter how large the system (City) is. It helps to distribute the load on the system (traffic jam) to the right server node with finesse.
Let's assume you are a civil engineer and you are planning the road network of a city. The key factors you have to keep in mind are you have to make the roads wider for more vehicles to pass at a time and a road chain to connect different roads.
Comparing this example with a system that is vertically scaled (making the road wider) and horizontally scaled (making the chain of roads). we also need to balance the load of requests sent to the node (traffic) with some approach.
Let's dive deep into this -
📍Important Keyterms
Nodes/Buckets - server which provides services
Hash Function - a function that is used to map data of arbitrary size to fixed-size values
Data Distribution/ partitioning - a process to distribute the data across various nodes to boost the performance and scalability of the system
Hotspot - A performance-degraded node in a distributed system due to a large share of data storage and a high volume of retrieval or requests
#️⃣Hashing
Let's get back to the road traffic example - assume that 100 people are going to the same destination in a city at the same time. But they can't go side by side with the same road, because it will create a traffic jam on that road. So they are using special GPS software that can redirect them to the same destination but distribute the roots by assigning them uniformly. The distribution is based on a unique ID which is assigned to 100 people by the GPS. That technique is called hashing.
Hashing is a technique that is used to uniquely identify a specific object from a group of similar objects. An ideal hash function generates a unique key for every element.
Let's start optimizing the systems load -
Key range partitioning *️⃣
If clients are sending requests to servers then each request must contain some request ID within it. But the request ID might be anything and we need to establish a way to connect these requests with nodes balancing the traffic.
So we are using the Hash function to generate a particular number based on the request ID (r1).
h(r1) = m // By hashing we are getting a particular number
m can be mapped to a particular server by taking the remainder of the modulo division by the number of servers (n) in the system.
m % n
the request will be sent to a particular server of (m % n) server ID. So if there is k number of requests the load of the server will be k/n where 1/n is the load factor.
Now If we add an extra server to our system then there will be some problem regarding ID assignment. Because now there are (n+1) servers and clients are sending requests, all the requests will be rehashed in the system which will cause the local cache a total waste. because every time we are scaling up our system, the requests are getting assigned to a new server again and again. It degrades the performance of the entire system.
if we imagine the change in request distribution with a pie chart then it will be something like this -

Now that's a problem in efficiency POV. We need a more advanced process to handle this and that is Consistent Hashing.
Consistent Hashing #️⃣
It's clear that if we depend on the number of servers then it will be difficult to manage [ h(r1) % n ]. So let's remove the server number from the process.
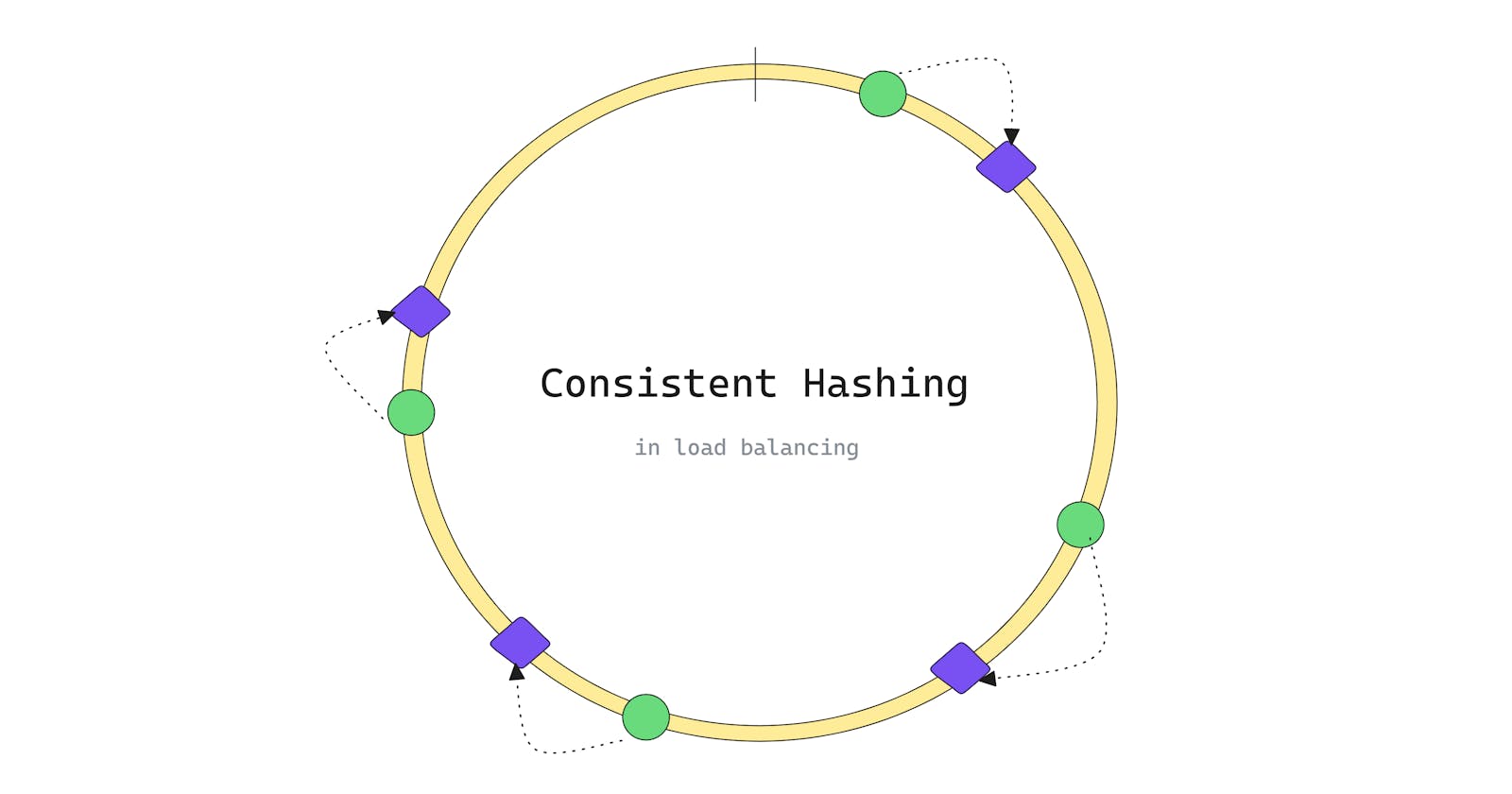
Now we are considering a ring-like structure and using the hash function we are hashing all the server IDs to generate a particular number. Based on the number index we are assigning servers to particular nodes on the circle. Now using the same hash function we are hashing the request IDs to get an index on the virtual hash ring.
All the requests will be assigned to its nearest node in a clockwise direction.

if we remove a node then the requests associated with that node will be assigned to its next nearest node in a clockwise direction without reallocating other request-node connections on the hash ring. The same thing will happen if we add an extra node to the hash ring the nearest request-node connection will be relocated only, rest of the data-retrieving connections will be the same.


Virtual Nodes
Sometimes, for removing and adding nodes load increased for one particular node. In that case, consistent hashing allows the distribution of data across clusters to minimize the rearrangement by creating virtual nodes on the hash ring.
So, Consistent hashing is a distributed systems technique that operates by assigning the data objects and nodes a position on a virtual ring structure (hash ring). Consistent hashing minimizes the number of keys to be remapped when the total number of nodes changes.